Sdcb Chats 技術博客:數據庫 ID 選型的曲折之路 - 從 Guid 到自增 ID,再到 Guid
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
在軟件開發中,數據庫主鍵的選擇,Guid 還是自增整數 ID,一直是一個備受開發者關注和討論的經典話題。作為開源 ChatGPT 前端項目 Sdcb Chats 的開發者,我們在這個問題上也經歷了一系列探索和演進,頗具代表性。Sdcb Chats 項目致力于打造一個強大、易用、可高度定制的 ChatGPT 及大語言模型前端,幫助用戶輕松連接、管理和使用各種主流的大語言模型。 總的來說,Sdcb Chats 的 ID 策略經歷了從最初使用 Guid,到遷移至自增 ID,再到界面顯示加密 ID,最終又回歸到界面顯示 Guid 的過程,其中蘊含著許多有趣的思考和實踐經驗,也反映了我們在項目迭代過程中對性能、安全和用戶體驗的不斷權衡與優化。
第一階段 - 擁抱 Guid:“一步到位”的方案項目初期,我的好友 G 負責總體系統設計,包括前端和數據庫。他果斷選擇了 Guid 作為主鍵方案。這在當時是很自然的選擇,因為在普遍的技術認知中,自增 ID 在分布式系統中似乎存在諸多不便,而 Guid(全局唯一標識符)則被視為一種更現代、更通用的解決方案。Guid 的核心優勢在于其全局唯一性,能夠在不同的數據庫和服務器之間獨立生成,無需擔心 ID 沖突問題。 以下是項目初期基于 PostgreSQL 設計的數據庫創建腳本鏈接(如果您感興趣可以查看): 例如,這是 然而,隨著項目的深入發展,Guid 方案的一些局限性逐漸顯現。首先,Guid 較長的長度和復雜的結構在某些場景下給數據庫性能帶來了一定負擔。尤其是在數據量快速增長的情況下,索引體積增大,查詢速度變慢等問題開始凸顯。作為負責維護公司內部 Chats 數據庫服務器的人,我注意到核心表 第二階段 - 性能至上:遷移至自增 IDChats 項目的重構是一項系統性工程,數據庫的大規模重構只是其中關鍵環節之一。實際上,軟件重構是一個持續迭代的過程,貫穿于項目的整個生命周期。 在我看來,項目重構如同軟件的自我革新,需要開發者具備“刀刃向內”的勇氣和決心。當我們審視代碼,發現不足之處,就如同在前進的道路上遇到了障礙。我們當然可以選擇繞行,暫時規避問題,但這些技術債務會像隱患一樣潛伏下來,并在未來某個時刻影響系統的穩定性和可維護性。特別是對于數據庫這種核心模塊,開發者往往出于謹慎,傾向于避免改動既有結構和數據。但長此以往,問題會逐漸累積,最終侵蝕系統的健康。因此,正視并解決這些問題才是負責任的做法。 當然,在 Chats 項目的重構中,我也有著得天獨厚的優勢。作為后端設計的主導者和核心開發者,我對系統的每一個細節都了如指掌。正所謂“船小好調頭”,即使是數據庫大規模遷移這樣的“大手術”,我也能快速決策、高效執行。事實上,Chats 數據庫已經經歷過多次重要的數據遷移,各位可以通過項目倉庫中的數據庫遷移腳本了解詳情:https://github.com/sdcb/chats/tree/ebefd93cb187961f8c69dcf04163433ce753a5f3/src/scripts/db-migration。 將主鍵從 Guid 切換為自增 int ID,最直接的好處就是性能的提升,具體體現在以下幾個方面:
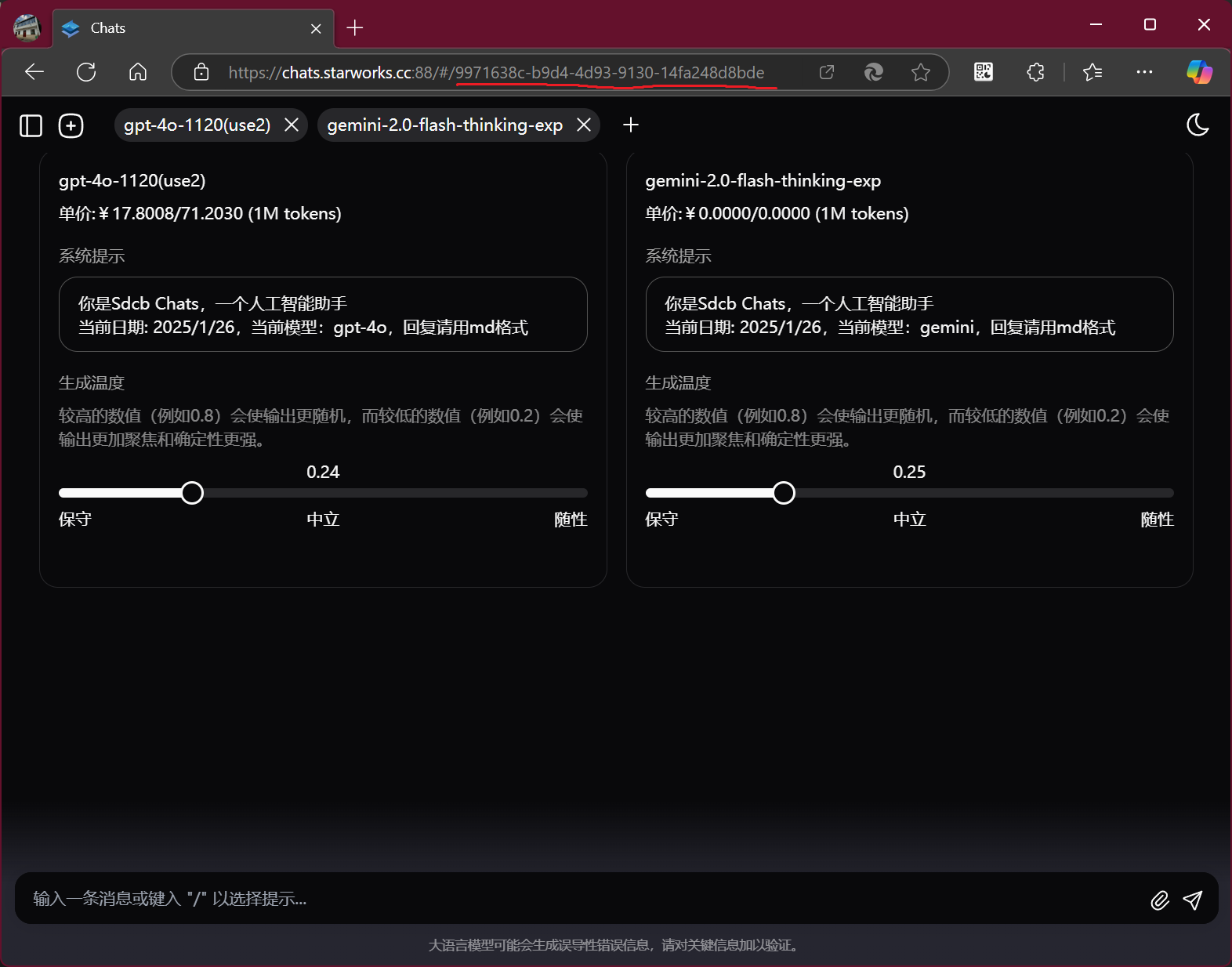
當然,從 Guid 遷移到自增 ID 并非一帆風順,最大的挑戰在于數據遷移的復雜性。我們需要編寫嚴謹的數據遷移腳本,確保數據遷移過程中數據的一致性和完整性不受破壞。同時,還需要仔細評估遷移可能帶來的業務影響,例如外鍵關聯的更新,以及應用程序代碼的調整。幸運的是,正如前面提到的,Chats 項目已經積累了多次數據庫遷移的經驗,這為我們這次從 Guid 到自增 ID 的遷移奠定了堅實的基礎。 例如,這段 339 行的 C# 數據庫遷移腳本(在 LINQPad 中編寫): 在遷移腳本中,我們使用了類似 通過這樣的映射,我們可以在數據遷移過程中,將舊的 Guid 主鍵平滑地轉換為新的自增 ID,并確保數據關聯關系的正確性。 第三階段 - 安全升級:界面 ID 加密完成數據庫主鍵從 Guid 到自增 ID 的遷移后,我們又面臨了新的問題:如何在用戶界面上安全地展示 ID。最初,我們直接沿用了數據庫的自增 ID,將其暴露在前端界面和 API 接口中。然而,這種做法很快引發了一些安全性和用戶體驗方面的問題。 例如,當創建一個新的聊天會話時,界面 URL 可能會顯示為 此外,從用戶體驗的角度來看,連續的數字 ID 也顯得不夠專業和優雅。用戶可能會覺得這些 ID 過于簡單和隨意,與他們對現代聊天應用的期望不符。 為了解決這些問題,我們決定對界面上顯示的 ID 進行加密處理。 最初,我使用了這段 C# 代碼來實現整數 ID 的加密: 在這個實現中,整數 ID 首先被轉換為小端序的字節數組,然后使用 AES 算法的 CBC 模式進行加密。加密后的數據被編碼為 Base64 URL 格式,以便在 URL 中安全傳輸。最終,URL 可能呈現為如下形式: 通過這種加密方式,我們不僅提升了系統的安全性,也改善了用戶體驗。加密后的 ID 看起來更加復雜和專業,有效避免了簡單數字序列帶來的潛在問題。 其中,初始化向量 IV 的生成方式如下。我定義了一個 每個枚舉值代表一種加密目的。代碼會根據不同的目的生成不同的 IV。這樣做的目的是確保即使同一個整數 ID 在不同的上下文(例如 ChatId 和 FileId)中被加密,也會產生不同的加密結果。這種做法提升了安全性和靈活性,我們可以在不同的場景下復用相同的加密機制,而無需擔心 ID 重復或沖突。 可能有朋友會問,為什么不使用隨機 IV,并將 IV 添加到加密后的 ID 中,這樣安全性不是更高嗎?這主要是基于以下兩點考慮: 首先,前端的某些計算邏輯依賴于穩定的 ID。在我們的前端代碼中,特別是在聊天會話管理和消息渲染方面,我們大量使用了基于 ID 的緩存和狀態管理機制。例如,當用戶在一個聊天窗口中滾動瀏覽消息時,前端會根據消息的 ID 來渲染消息之間的父子關系。如果使用隨機 IV,即使是同一個聊天會話,在不同的時間或不同的上下文中被加密,生成的 ID 都會不同。這會導致前端緩存失效,狀態管理混亂,最終引發難以追蹤的 bug。想象一下,用戶明明還在同一個聊天中,但由于 ID 變化,前端卻認為這是一個新的聊天,之前的消息緩存全部失效,這無疑會造成糟糕的用戶體驗。為了保證前端邏輯的穩定性和可預測性,我們需要確保在同一上下文中,同一個整數 ID 加密后的結果始終一致。 其次,不固定的 IV 會顯著增加 ID 的長度。如果將隨機生成的 IV 也附加到加密后的 ID 中,最終的 ID 長度會大大增加。AES 算法的 IV 通常為 16 字節,轉換為 Base64 URL 編碼后,會增加約 21 個字符的長度(16 * 4 / 3 ≈ 21.3)。原本加密后的 ID 已經比純數字 ID 長了不少,如果再加上 20 多個字符的 IV,整個 ID 會顯得非常臃腫,尤其是在 URL 中展示時,既不美觀,也增加了 URL 的長度負擔。我們希望在保證安全性的前提下,盡可能保持 ID 的簡潔易用。 因此,綜合考慮前端的穩定性和 ID 長度,我們最終選擇了使用基于 第四階段 - 兼顧用戶感知:界面顯示為 Guid(當前方案)經過一段時間的實際運行,我們意識到,雖然加密 ID 解決了安全性問題,但在某些場景下,用戶仍然希望看到一種更具辨識度的 ID 格式。因此,我們最終決定在界面上將 ID 顯示為 Guid 格式。 這種做法的優點在于,Guid 格式的 ID 看起來更加隨機和復雜,更符合用戶對現代應用的普遍認知,同時也有效避免了直接暴露自增 ID 的問題。在具體實現上,我們將加密后的 ID 轉換為 Guid 格式進行展示。這樣一來,用戶在界面上看到的 ID 既安全又專業。 細心的朋友可能已經注意到,由于我的輸入長度為 4 字節或 8 字節(分別對應 int32 和 int64 類型的 ID),AES CBC 加密后的輸出長度固定為 16 字節(但前端代碼額外增加了一個字節作為版本號前綴,固定為 0)。而一個 Guid 的長度恰好也是 16 字節。因此,只需將 Base64Url 序列化方式替換為 Guid 序列化,即可輕松將加密 ID 轉換為 Guid 形式: https://github.com/sdcb/chats/blob/r-407/src/BE/Services/UrlEncryption/Utils.cs#L50-L60 可能有朋友會進一步追問,為什么堅持使用 AES CBC 算法,而不是現在更流行的 AES GCM 算法呢?這又可以展開一篇長文討論。簡單來說: 首先,AES GCM 的隨機性高度依賴于 nonce 的唯一性。Nonce(Number used once)是一個一次性使用的隨機數,在 AES GCM 中扮演著至關重要的角色,類似于 AES CBC 中的 IV(Initialization Vector,初始化向量)。如果 nonce 在多次加密中重復使用,尤其是在加密序列化的、遞增的 ID 時,AES GCM 的安全性會大打折扣,甚至可能暴露出加密模式的規律性。 在我們的場景中,雖然我們為每種 為了更直觀地說明問題,請看以下 C# 代碼示例: 輸出結果如下: 請注意觀察 相比之下,AES CBC 雖然也依賴 IV,但即使 IV 固定,只要密鑰安全,其加密結果的隨機性依然能得到較好的保證。尤其是在我們使用了填充模式(Padding)的情況下,即使輸入數據存在一定的規律性,也能有效地隱藏這種規律。 其次,AES GCM 的輸出長度會顯著增加,難以適配 Guid 格式。AES GCM 在提供加密功能的同時,還提供了數據完整性校驗功能,這是通過附加一個認證標簽(Authentication Tag,簡稱 Tag)來實現的。這個 Tag 通常是 12 到 16 字節,用于驗證數據的完整性和真實性,防止數據被篡改。除了 Tag 之外,AES GCM 還需要一個顯式的 nonce 作為輸入。對于我們來說,nonce 至少需要 12 字節才能保證足夠的安全性。 這意味著,如果我們使用 AES GCM 加密一個 4 字節的 int32 ID,最終的輸出長度將至少是:4 字節(密文) + 12 字節(nonce) + 12 字節(最小 Tag 大小) = 28 字節。即使我們加密一個 8 字節的 int64 ID,輸出長度也會超過 32 字節。這樣的長度,無論如何都無法直接塞到一個 16 字節的 Guid 中。而且,為了將 nonce 和 tag 都塞進去,我們勢必需要設計更復雜的序列化方案,這會增加前端和后端的處理復雜度,也可能導致 ID 格式的不統一,例如一部分 ID 是 Guid,一部分是更長的 Base64 編碼字符串,這會給前端開發帶來額外的困擾。 我們之所以最終選擇將加密后的 ID 展示為 Guid 格式,一個重要的考量就是希望保持 ID 的統一性和簡潔性。Guid 作為一個 16 字節的固定長度標識符,在很多場景下都非常方便使用和處理。如果我們為了追求 AES GCM 的“更高安全性”而犧牲了 ID 的簡潔性和統一性,反而可能會得不償失。 最后,AES GCM 的額外安全優勢在我們的應用場景下并非不可或缺。AES GCM 最主要的優勢在于它提供的認證加密(Authenticated Encryption)功能,即在加密的同時,也保證了數據的完整性和真實性。這意味著,如果數據在傳輸過程中被篡改,解密時會立即發現并報錯。這種認證功能對于一些對數據完整性要求極高的場景非常重要,例如金融交易、電子簽名等。 然而,在我們的 Chats 應用中,我們對 ID 的安全性需求主要集中在防止惡意猜測和未經授權的訪問,而不是防止數據篡改。即使加密后的 ID 在傳輸過程中被篡改,最終解密出來的 ID 也大概率無法在數據庫中找到對應的記錄,或者即使找到了,后續的業務邏輯也會進行權限驗證,確保用戶只能訪問自己擁有的聊天或消息。 更重要的是,即使我們使用 AES CBC,也并非完全沒有數據完整性驗證機制。首先,AES CBC 配合填充模式(例如 PKCS7 Padding)本身就提供了一定程度的完整性校驗。對于 int32 類型的 ID,AES CBC 加密后會生成 16 字節的密文,其中有 12 字節實際上是填充數據。如果密文被篡改,解密時填充校驗會失敗,從而可以檢測到數據損壞。雖然這種校驗強度不如 AES GCM 的 Tag 那么高,但也足以應對一般的篡改嘗試。 其次,在我們的系統中,解密后的 ID 最終會用于數據庫查詢。即使攻擊者能夠繞過 AES CBC 的填充校驗,篡改了加密后的 ID,解密出來的錯誤 ID 在數據庫中大概率也找不到對應的記錄。即使碰巧找到了記錄,我們也會在數據庫層面和業務邏輯層面進行多重權限驗證,確保數據的安全性。 因此,綜合考慮以上三點,我們最終權衡之后,仍然選擇了 AES CBC 算法。它在保證足夠安全性的前提下,能夠生成 16 字節的密文,完美適配 Guid 格式,并且實現相對簡單,性能也更優。當然,技術選型永遠是一個不斷演進的過程,未來如果我們的安全需求發生變化,或者 AES GCM 在性能和易用性方面有了新的提升,我們也不排除會重新評估并切換到 AES GCM 的可能性。 總結與展望回顧 Sdcb Chats 項目 ID 演進的四個階段,從最初擁抱 Guid 的“一步到位”,到為了性能考量轉向自增 ID,再到為了安全和體驗在界面上加密 ID,最終又回歸到使用 Guid 形式展示,這的確是一段曲折而又充滿思考的旅程。 在這個過程中,我們不斷地在性能、安全性、用戶體驗和開發效率之間權衡取舍。沒有一勞永逸的完美方案,只有在持續迭代和演進中,才能找到最適合當前階段的最佳實踐。每一次看似“倒退”的改動,實際上都基于更深入的理解和更全面的考量。例如,從 Guid 到自增 ID 的轉變,是為了解決實際存在的數據庫性能瓶頸;而界面上從加密 ID 到 Guid 的回歸,則是在安全性得到保障的前提下,更好地滿足用戶對“現代感”和“專業性”的用戶感知。 這段經歷也印證了軟件開發中一個重要的理念:沒有銀彈。技術選型需要結合具體的應用場景和需求,持續地監控和評估,并根據實際情況靈活調整。我們不能因為“大家都說 Guid 好”就盲目跟風,也不能因為“性能至上”就忽略安全性和用戶體驗。只有深入理解各種方案的優缺點,才能做出最明智的選擇。 而 Sdcb Chats 項目的 ID 演進之路,也正是開源項目不斷迭代、持續進化的一個縮影。我們始終秉持著開放、務實的態度,積極擁抱變化,勇于嘗試新的技術方案,并不斷地從實踐中總結經驗教訓。 如果您對我們這曲折的 ID 選型故事,以及 Sdcb Chats 項目本身感興趣,歡迎繼續了解! Sdcb Chats:一個強大的開源 ChatGPT 前端 我是開源項目 Sdcb Chats 的作者。Sdcb Chats 定位為一個強大且易于部署的 ChatGPT 前端,旨在幫助用戶輕松接入和管理各種主流的大語言模型。 Sdcb Chats 的主要特性包括:
無論您是個人開發者、技術愛好者,還是企業用戶,Sdcb Chats 都能為您提供一個強大、靈活、易用的 ChatGPT 前端解決方案。 如果您覺得 Sdcb Chats 對您有所幫助,或者您認同我們的技術理念和開源精神,請在 GitHub 上給我們一個 Star ?。您的支持是我們持續前進的最大動力! GitHub 倉庫地址: https://github.com/sdcb/chats 希望這篇博客和項目介紹能幫助您對 Sdcb Chats 項目有更深入的了解。期待您的關注和參與,讓我們一起打造更優秀的開源項目! 轉自https://www.cnblogs.com/sdcb/p/18691585/sdcb-chats-id-in-url 該文章在 2025/2/5 9:49:38 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886