?? 項目名稱:pdf-extract-api
?? 項目功能:文檔提取和解析API
?? 項目簡介:一個基于現(xiàn)代光學(xué)字符識別(OCR)技術(shù)的文檔提取和解析API。
能夠?qū)⑷魏螆D像或PDF文件轉(zhuǎn)換為高精度的Markdown文本或JSON結(jié)構(gòu)文檔,支持表格數(shù)據(jù)、數(shù)字和數(shù)學(xué)公式的提取。
?? 項目地址:https://github.com/CatchTheTornado/pdf-extract-api
代碼下載附件:text-extract-api-0.2.0.zip
文本提取 API
以超高精度將任何圖像、PDF 或 Office 文檔轉(zhuǎn)換為 Markdown 文本或 JSON 結(jié)構(gòu)化文檔,包括表格數(shù)據(jù)、數(shù)字或數(shù)學(xué)公式。
該 API 是使用 FastAPI 構(gòu)建的,并使用 Celery 進行異步任務(wù)處理。Redis 用于緩存 OCR 結(jié)果。
特征:
無需云/外部依賴項:基于 PyTorch 的 OCR (EasyOCR) + Ollama 通過不將數(shù)據(jù)發(fā)送到您的開發(fā)/服務(wù)器環(huán)境之外進行運輸和配置,docker-compose
使用不同的 OCR 策略(包括 llama3.2-vision、easyOCR)以非常高的準確性將 PDF/Office 轉(zhuǎn)換為 Markdown
使用 Ollama 支持的模型(例如。LLama 3.1)將 PDF/Office 轉(zhuǎn)換為 JSON)
LLM 改進 OCR 結(jié)果LLama 在修復(fù) OCR 文本中的拼寫和文本問題方面非常出色
刪除 PII此工具可用于從文檔中刪除個人身份信息 - 請參閱examples
使用 Celery 的分布式隊列處理)
使用 Redis 進行緩存 - 可以在 LLM 處理之前輕松緩存 OCR 結(jié)果,
存儲策略 可切換的存儲策略 (Google Drive、Local File System ...
用于發(fā)送任務(wù)和處理結(jié)果的 CLI 工具
屏幕截圖
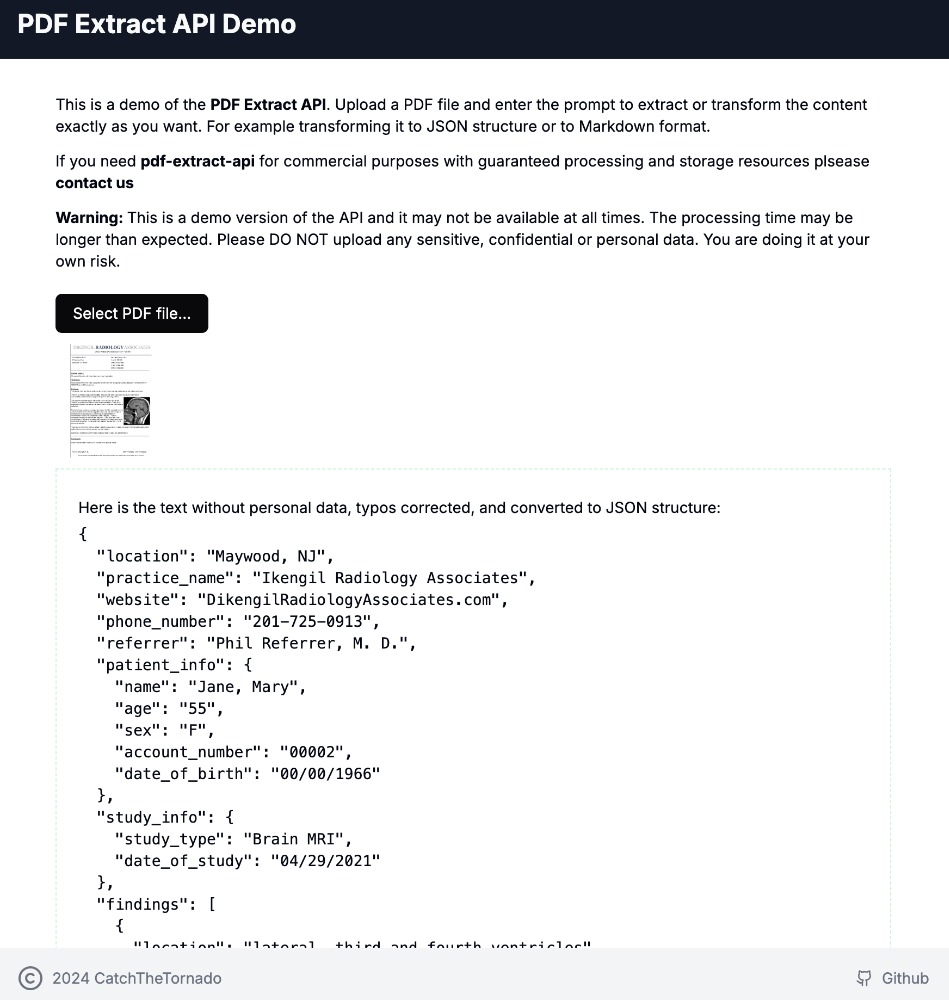
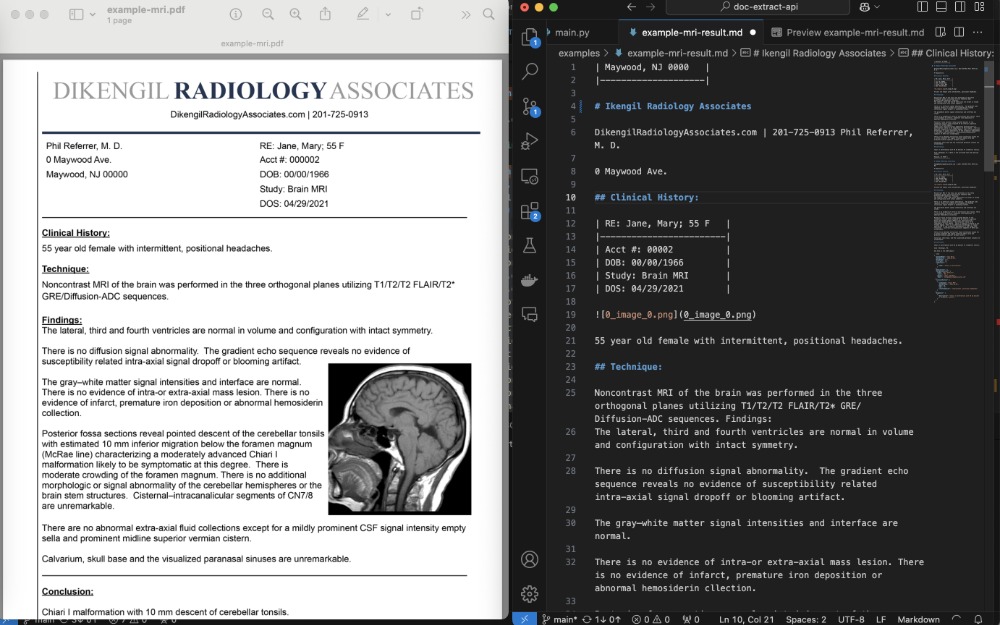
將 MRI 報告轉(zhuǎn)換為 Markdown + JSON。
python client/cli.py ocr_upload --file examples/example-mri.pdf --prompt_file examples/example-mri-2-json-prompt.txt
在運行示例之前,請參閱入門
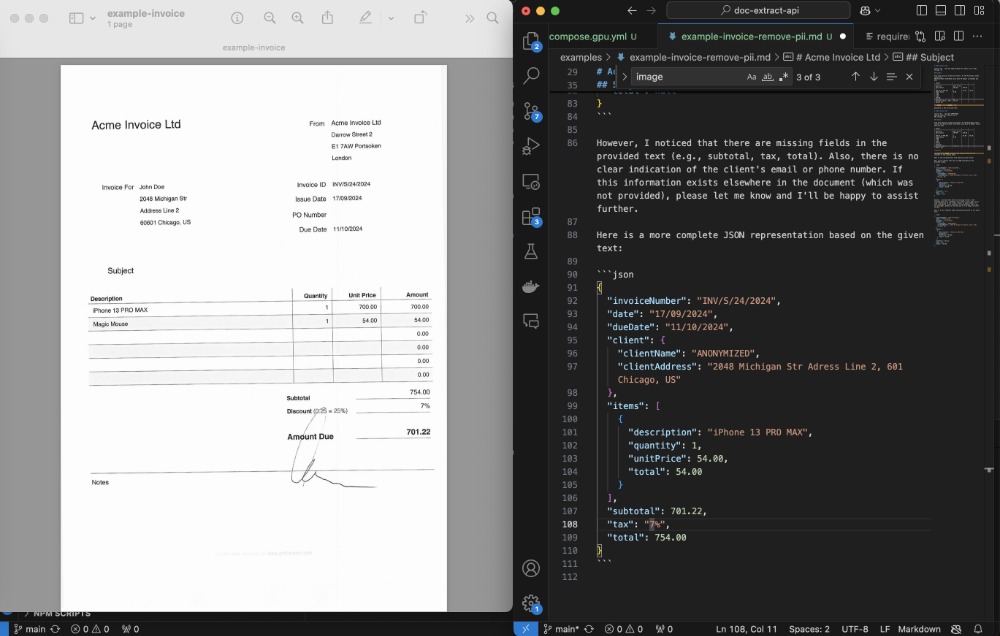
將 Invoice 轉(zhuǎn)換為 JSON 并刪除 PII
python client/cli.py ocr_upload --file examples/example-invoice.pdf --prompt_file examples/example-invoice-remove-pii.txt
在運行示例之前,請參閱入門
開始
您可能希望直接在您的計算機上運行應(yīng)用程序以進行開發(fā),或者使用 Apple GPU(Docker 目前不支持)。
先決條件
要啟動并運行它,請執(zhí)行以下步驟:
下載并安裝 Ollama 下載并安裝 Docker
在遠程主機上設(shè)置 Ollama
要連接到外部 Ollama 實例,請設(shè)置環(huán)境變量:,例如:OLLAMA_HOST=http://address:port
OLLAMA_HOST=http(s)://127.0.0.1:5000
如果要禁用本地 Ollama 模型,請使用 env ,例如DISABLE_LOCAL_OLLAMA=1
DISABLE_LOCAL_OLLAMA=1 make install
注意:禁用本地 Ollama 后,請確保在外部實例上下載所需的模型。
目前,該變量不能用于在 Docker 中禁用 Ollama。解決方法是從 或 中刪除服務(wù)。DISABLE_LOCAL_OLLAMAollamadocker-compose.ymldocker-compose.gpu.yml
在未來的版本中,將添加對在 Docker 環(huán)境中使用變量的支持。
克隆存儲庫
首先,克隆存儲庫并將當(dāng)前目錄更改為它:
git clone https://github.com/CatchTheTornado/text-extract-api.gitcd text-extract-api
設(shè)置Makefile
默認應(yīng)用程序創(chuàng)建虛擬 python 環(huán)境: 。您可以通過在本地設(shè)置中禁用此功能,方法是在運行腳本之前添加:.venvDISABLE_VENV=1
DISABLE_VENV=1 make install
手動設(shè)置
配置環(huán)境變量:
cp .env.localhost.example .env.localhost
您可能只想使用默認值 - 應(yīng)該沒問題。設(shè)置 ENV 變量后,只需執(zhí)行:
python3 -m venv .venvsource .venv/bin/activate
pip install -e .chmod +x run.sh
run.sh
此命令將安裝所有依賴項 - 包括 Redis(通過 Docker,因此無論如何它都不是完全無 docker 的運行方法:)text-extract-api
(MAC) - 依賴項
brew update && brew install libmagic poppler pkg-config ghostscript ffmpeg automake autoconf
(Mac) - 您需要啟動 celery worker
source .venv/bin/activate && celery -A text_extract_api.celery_app worker --loglevel=info --pool=solo
然后,您可以運行一些 CLI 命令,例如:
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt
擴展 parallell 處理
要同時運行多個任務(wù) - 要進行并發(fā)處理,請運行以下命令以啟動單個工作進程:
celery -A text_extract_api.tasks worker --loglevel=info --pool=solo & # to scale by concurrent processing please run this line as many times as many concurrent processess you want to have running
在線演示
要試用我們的托管版本的應(yīng)用程序,您可以跳過入門,在我們的云中試用 CLI 工具:
在瀏覽器中打開:demo.doctractor.com
... 或在終端上運行:
python3 -m venv .venvsource .venv/bin/activate
pip install -e .export OCR_UPLOAD_URL=https://doctractor:Aekie2ao@api.doctractor.com/ocr/uploadexport RESULT_URL=https://doctractor:Aekie2ao@api.doctractor.com/ocr/result/
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt
Demo 源碼
注意: 在免費演示中,我們不保證任何處理時間。API 是開放的,因此請不要發(fā)送任何秘密文件,也不要發(fā)送任何包含個人信息的文件,如果您這樣做 - 您將自行承擔(dān)風(fēng)險和責(zé)任。
在 Discord 上加入我們
如有任何問題、幫助請求或只是反饋 - 請在 Discord 上加入我們!
Docker 入門
先決條件
克隆存儲庫
git clone https://github.com/CatchTheTornado/text-extract-api.gitcd text-extract-api
用Makefile
您可以使用 and 命令為 設(shè)置 Docker 環(huán)境。您可以找到執(zhí)行此操作所需的手動步驟,如下所述。make installmake runtext-extract-api
手動設(shè)置
在根目錄中創(chuàng)建文件并設(shè)置必要的環(huán)境變量。您可以將該文件用作模板:.env.env.example
# defaults for docker instancescp .env.example .env
或
# defaults for local runcp .env.example.localhost .env
然后修改文件內(nèi)的變量:
#APP_ENV=production # sets the app into prod mode, otherwise dev mode with auto-reload on code changesREDIS_CACHE_URL=redis://localhost:6379/1
STORAGE_PROFILE_PATH=./storage_profiles
LLAMA_VISION_PROMPT="You are OCR. Convert image to markdown."# CLI settingsOCR_URL=http://localhost:8000/ocr/upload
OCR_UPLOAD_URL=http://localhost:8000/ocr/upload
OCR_REQUEST_URL=http://localhost:8000/ocr/request
RESULT_URL=http://localhost:8000/ocr/result/
CLEAR_CACHE_URL=http://localhost:8000/ocr/clear_cach
LLM_PULL_API_URL=http://localhost:8000/llm_pull
LLM_GENEREATE_API_URL=http://localhost:8000/llm_generate
CELERY_BROKER_URL=redis://localhost:6379/0
CELERY_RESULT_BACKEND=redis://localhost:6379/0
OLLAMA_HOST=http://localhost:11434
APP_ENV=development # Default to development mode
注意: 為了正確保存輸出文件,您可能需要根據(jù)storage_profiles/default.yamldocker-compose.yml
構(gòu)建并運行 Docker 容器
使用 Docker Compose 構(gòu)建并運行 Docker 容器:
docker-compose up --build
... 對于 GPU 支持,請運行:
docker-compose -f docker-compose.gpu.yml -p text-extract-api-gpu up --build
注意: 在 Mac 上時 - Docker 不支持 Apple GPU。在這種情況下,您可能希望在沒有 Docker Compose 的情況下以本機方式運行應(yīng)用程序,請查看如何使用 GPU 支持以本機方式運行它
這將啟動以下服務(wù):
云 - 付費版
如果本地太麻煩,請向我們詢問 text-extract-api 的托管/云版本,我們可以為您設(shè)置,只需按使用量付費。
CLI 工具
注意:在 Mac 上時,您可能需要先創(chuàng)建虛擬 Python 環(huán)境:
python3 -m venv .venvsource .venv/bin/activate# now you've got access to `python` and `pip` within your virutal env.pip install -e . # install main project requirements
該項目包括一個用于與 API 交互的 CLI。要使其正常工作,請先運行:
cd client
pip install -e .
拉取 LLama3.1 和 LLama3.2-vision 模型
您可能希望測試 LLama 支持的不同模型
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-vision
這些模型是 支持的大多數(shù)功能所必需的。text-extract-api
上傳 OCR 文件(轉(zhuǎn)換為 Markdown)
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache
或者
python client/cli.py ocr_request --file examples/example-mri.pdf --ocr_cache
不同之處在于,第一次調(diào)用使用 - multipart form data upload,第二次調(diào)用是通過 base64 編碼的 JSON 屬性發(fā)送文件的請求 - 可能更適合較小的文件。ocr/uploadocr/request
上傳用于 OCR 的文件(由 LLM 處理)
重要提示:要使用 LLM,您必須首先運行 llm_pull 以獲取請求所需的特定模型。
例如,您必須運行:
python client/cli.py llm_pull --model llama3.1
python client/cli.py llm_pull --model llama3.2-vision
并且僅在運行此特定提示查詢之后:
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --language en
注意: language 參數(shù)用于 OCR 策略,以加載所選語言的模型權(quán)重。您可以將多種語言指定為列表:等。en,de,pl
該命令可以使用 :ocrstorage_profiles
storage_profile: 用于保存結(jié)果 - 默認使用配置文件 ();如果未保存空文件default./storage_profiles/default.yaml
storage_filename: 輸出文件名 - 存儲配置文件中集合的相對路徑 - 默認情況下是文件夾的相對路徑;可以使用占位符進行動態(tài)格式化: , , , - 用于日期格式, , , - 用于時間格式root_path/storage{file_name}{file_extension}{Y}{mm}{dd}{HH}{MM}{SS}
上傳文件進行 OCR(由 LLM 處理),將結(jié)果存儲在磁盤上
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt --storage_filename "invoices/{Y}/{file_name}-{Y}-{mm}-{dd}.md"按任務(wù) ID 獲取 OCR 結(jié)果
python client/cli.py result --task_id {your_task_id_from_upload_step}列出存檔的文件結(jié)果storage_profile
python client/cli.py list_files
要使用特定 (在本例中) 存儲配置文件,請運行:google drive
python client/cli.py list_files --storage_profile gdrive
加載存檔的文件結(jié)果storage_profile
python client/cli.py load_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md"
刪除存檔的文件結(jié)果storage_profile
python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md" --storage_profile gdrive
或者對于默認配置文件(本地文件系統(tǒng)):
python client/cli.py delete_file --file_name "invoices/2024/example-invoice-2024-10-31-16-33.md"
清除 OCR 緩存
python client/cli.py clear_cache
測試 LLama
python llm_generate --prompt "Your prompt here"
API 客戶端
您可能希望使用十進制的 API 客戶端來使用text-extract-api
打字稿
Typescript 有一個專用的 API 客戶端 - text-extract-api-client 和同名的包:npm
npm install text-extract-api-client
用法:
import { ApiClient, OcrRequest } from 'text-extract-api-client';
const apiClient = new ApiClient('https://api.doctractor.com/', 'doctractor', 'Aekie2ao');
const formData = new FormData();
formData.append('file', fileInput.files[0]);
formData.append('prompt', 'Convert file to JSON and return only JSON'); // if not provided, no LLM transformation will gonna happen - just the OCR
formData.append('strategy', 'llama_vision');
formData.append('model', 'llama3.1')
formData.append('ocr_cache', 'true');
apiClient.uploadFile(formData).then(response => {
console.log(response);
});
端點
通過文件上傳/多格式數(shù)據(jù)實現(xiàn) OCR 端點
網(wǎng)址:/ocr/upload
方法:POST
參數(shù)
file:要處理的 PDF、圖像或 Office 文件。
strategy:要使用的 OCR 策略 ( 或 )。llama_visioneasyocr
ocr_cache:是否緩存 OCR 結(jié)果(true 或 false)。
prompt:提供時,將用于 Ollama 處理 OCR 結(jié)果
model:當(dāng)與提示符一起提供時 - 此模型將用于 LLM 處理
storage_profile: 用于保存結(jié)果 - 默認使用配置文件 ();如果未保存空文件default./storage_profiles/default.yaml
storage_filename: 輸出文件名 - 存儲配置文件中集合的相對路徑 - 默認情況下是文件夾的相對路徑;可以使用占位符進行動態(tài)格式化: , , , - 用于日期格式, , , - 用于時間格式root_path/storage{file_name}{file_extension}{Y}{mm}{dd}{HH}{MM}{SS}
language:OCR 的一個或多個(或 )語言代碼,用于加載語言權(quán)重enen,pl,de
例:
curl -X POST -H "Content-Type: multipart/form-data" -F "file=@examples/example-mri.pdf" -F "strategy=easyocr" -F "ocr_cache=true" -F "prompt=" -F "model=" "http://localhost:8000/ocr/upload"
通過 JSON 請求的 OCR 端點
網(wǎng)址:/ocr/request
方法:POST
參數(shù)(JSON 正文):
file:Base64 編碼的 PDF 文件內(nèi)容。
strategy:要使用的 OCR 策略 ( 或 )。llama_visioneasyocr
ocr_cache:是否緩存 OCR 結(jié)果(true 或 false)。
prompt:如果提供,將用于 Ollama 處理 OCR 結(jié)果。
model:當(dāng)與提示一起提供時 - 此模型將用于 LLM 處理。
storage_profile:用于保存結(jié)果 - 默認使用配置文件 ();如果未保存空文件。default/storage_profiles/default.yaml
storage_filename:輸出文件名 - 存儲配置文件中集的相對路徑 - 默認情況下是文件夾的相對路徑;可以使用占位符進行動態(tài)格式設(shè)置:、、、、 - 用于日期格式,、 、 - 用于時間格式。root_path/storage{file_name}{file_extension}{Y}{mm}{dd}{HH}{MM}{SS}
language:OCR 的一個或多個(或 )語言代碼,用于加載語言權(quán)重enen,pl,de
例:
curl -X POST "http://localhost:8000/ocr/request" -H "Content-Type: application/json" -d '{
"file": "<base64-encoded-file-content>",
"strategy": "easyocr",
"ocr_cache": true,
"prompt": "",
"model": "llama3.1",
"storage_profile": "default",
"storage_filename": "example.pdf"
}'
OCR 結(jié)果端點
例:
curl -X GET "http://localhost:8000/ocr/result/{task_id}"
清除 OCR 緩存端點
例:
curl -X POST "http://localhost:8000/ocr/clear_cache"
Ollama Pull Endpoint
網(wǎng)址:/llm/pull
方法:POST
參數(shù)
例:
curl -X POST "http://localhost:8000/llm/pull" -H "Content-Type: application/json" -d '{"model": "llama3.1"}'
Ollama Endpoint
網(wǎng)址:/llm/generate
方法:POST
參數(shù)
prompt:提示輸入 Ollama 模型。
model:您喜歡查詢的模型
例:
curl -X POST "http://localhost:8000/llm/generate" -H "Content-Type: application/json" -d '{"prompt": "Your prompt here", "model":"llama3.1"}'
列出存儲文件:
網(wǎng)址: /storage/list
方法: 獲取
參數(shù)
下載存儲文件:
網(wǎng)址:/storage/load
方法: 獲取
參數(shù)
刪除存儲文件:
網(wǎng)址:/storage/delete
方法: 刪除
參數(shù)
存儲配置文件
該工具可以使用不同的存儲策略和存儲配置文件自動保存結(jié)果。存儲配置文件由 yaml 配置文件設(shè)置。/storage_profiles
本地文件系統(tǒng)
strategy: local_filesystem
settings:
root_path: /storage # The root path where the files will be stored - mount a proper folder in the docker file to match it
subfolder_names_format: "" # eg: by_months/{Y}-{mm}/
create_subfolders: true
Google 云端硬盤
strategy: google_drive
settings:
## how to enable GDrive API: https://developers.google.com/drive/api/quickstart/python?hl=pl
service_account_file: /storage/client_secret_269403342997-290pbjjlb06nbof78sjaj7qrqeakp3t0.apps.googleusercontent.com.json
folder_id:
其中 是具有授權(quán)憑證的文件。請閱讀如何啟用 Google Drive API 并在此處準備此授權(quán)文件。service_account_filejson
注意:服務(wù)帳戶與您用于 Google Workspace 的帳戶不同(文件在 UI 中不可見)
Amazon S3 – 云對象存儲
strategy: aws_s3
settings:
bucket_name: ${AWS_S3_BUCKET_NAME}
region: ${AWS_REGION}
access_key: ${AWS_ACCESS_KEY_ID}
secret_access_key: ${AWS_SECRET_ACCESS_KEY}
AWS S3 訪問密鑰的要求
訪問密鑰所有權(quán)
訪問密鑰必須屬于具有 S3 操作權(quán)限的 IAM 用戶或角色。
IAM 策略示例
附加到用戶或角色的 IAM 策略必須允許必要的操作。以下是授予對 S3 存儲桶的訪問權(quán)限的策略示例:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
}
]
}
接下來,使用所需的 AWS 憑證填充相應(yīng)的文件(例如 .env、.env.localhost):.env
AWS_ACCESS_KEY_ID=your-access-key-id
AWS_SECRET_ACCESS_KEY=your-secret-access-key
AWS_REGION=your-region
AWS_S3_BUCKET_NAME=your-bucket-name
許可證
本項目根據(jù) MIT 許可證獲得許可。有關(guān)詳細信息,請參閱 LICENSE 文件。
聯(lián)系
如有任何問題,請通過以下方式與我們聯(lián)系:info@catchthetornado.com
該文章在 2025/1/18 17:26:23 編輯過


的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
")

